Construyendo un Agente Inteligente para Copilot Studio con Azure AI Foundry y Python
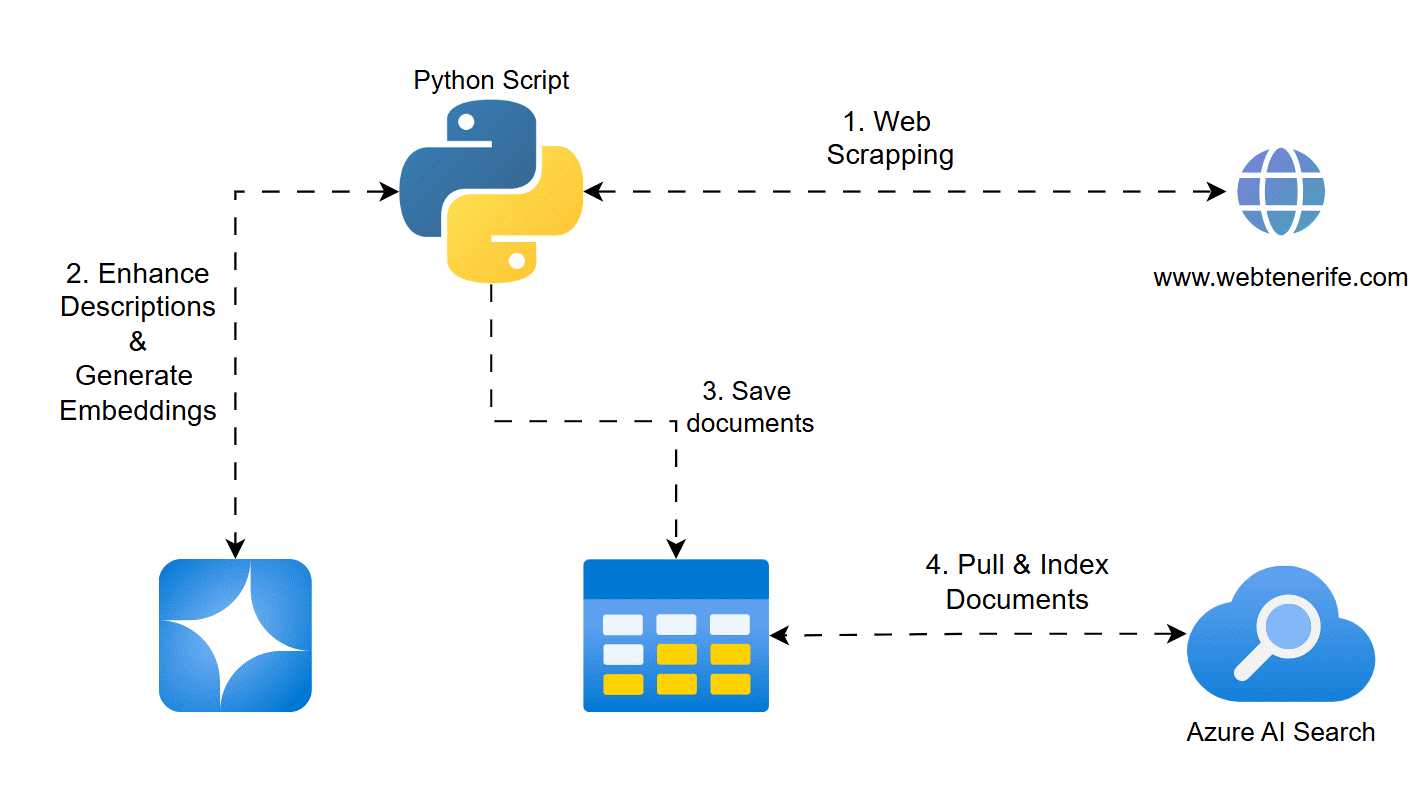
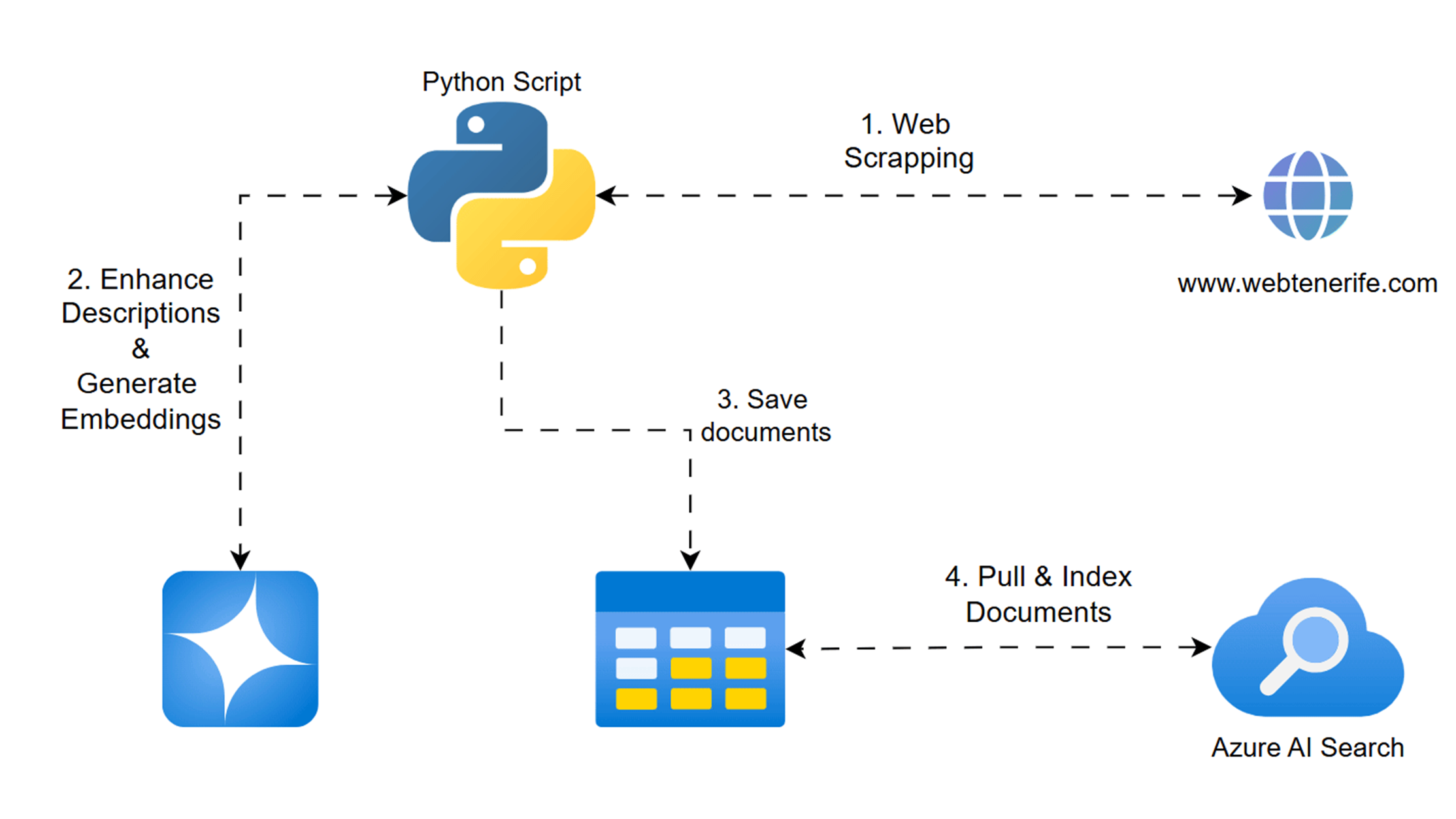
Si te interesa la inteligencia artificial y cómo crear agentes que complementen Copilot Studio, hoy te traigo algo que te va a encantar. En este artículo, te enseñaré cómo montar un pequeño agente en Python que recopila información turística de Tenerife, la enriquece con Azure AI Foundry, la vectoriza y la sube a Azure AI Search para que pueda ser utilizada como conocimiento en un chatbot de Copilot Studio.
Vamos a utilizar Python y Playwright para hacer webscraping, GPT-4o mini en Azure AI Foundry para mejorar las descripciones de los lugares turísticos, Azure OpenAI Embeddings para vectorizar la información y Azure Blob Storage y Azure Table Storage para almacenar los datos. Finalmente, en un segundo artículo, te enseñaré cómo indexar esta información en Azure AI Search y hacer que tu Copilot pueda entender y responder sobre ella.
Este es el tipo de cosas que enseñaremos en el Canadian Power Platform Summit en Vancouver, donde David Lorenzo y yo mostraremos cómo usar Copilot Studio junto con Azure AI Foundry para crear soluciones avanzadas. Así que, si te gusta experimentar con IA, bases de datos vectoriales y asistentes inteligentes, quédate y empecemos a construir este agente paso a paso.
Con este agente, buscamos:
- Mejorar la experiencia del usuario: Al enriquecer las descripciones turísticas, el agente ofrece información más completa y persuasiva, ayudando a los visitantes a tomar decisiones informadas.
- Automatizar procesos: Mediante el uso de webscraping y procesamiento automatizado, eliminamos la necesidad de actualizar manualmente la información.
- Facilitar búsquedas inteligentes: La vectorización y almacenamiento de los datos permiten que se puedan utilizar en motores de búsqueda avanzados como Azure AI Search, ofreciendo respuestas basadas en similitud y relevancia.
- Integrar múltiples tecnologías: El proyecto demuestra cómo combinar herramientas modernas como Playwright, Azure AI Foundry y Azure OpenAI, creando una solución para el sector turístico.
Paso 1: Configuración y Dependencias
El primer paso es preparar el entorno de desarrollo. Importamos las librerías necesarias y definimos las variables de configuración (como endpoints y claves) de forma genérica para que puedan adaptarse fácilmente a diferentes entornos. Esto permite mantener la seguridad y la flexibilidad en el despliegue.
import os
import json
import time
import math
import re
from playwright.sync_api import sync_playwright
from urllib.parse import urljoin
import requests
from azure.storage.blob import BlobServiceClient
from azure.data.tables import TableServiceClient
from azure.core.exceptions import ResourceExistsError
# Configuración de Azure AI Foundry con variables genéricas
AZURE_FOUNDRY_ENDPOINT = os.getenv("AZURE_FOUNDRY_ENDPOINT", "https://<tu_endpoint_genérico>.openai.azure.com/")
AZURE_FOUNDRY_API_KEY = os.getenv("AZURE_FOUNDRY_API_KEY", "<tu_api_key_genérica>")
AZURE_FOUNDRY_DEPLOYMENT_NAME = os.getenv("AZURE_FOUNDRY_DEPLOYMENT_NAME", "gpt-4o-mini")
Consejo: Utiliza variables de entorno o archivos de configuración para gestionar claves y endpoints de manera segura.
Paso 2: Extracción de Información mediante Webscraping
En esta etapa, empleamos Playwright para automatizar la navegación a la web turística de Tenerife y extraer datos clave de cada categoría (nombre, descripción y enlace). El objetivo es recopilar toda la información básica que posteriormente enriqueceremos.
def scrape_categories():
print("Iniciando scraping de categorías...")
start_time = time.time()
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.set_extra_http_headers({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ..."
})
URL = "https://www.webtenerife.com/que-hacer/"
page.goto(URL)
page.wait_for_load_state("networkidle")
elements = page.query_selector_all("div.card__col article.card")
print(f"Categorías encontradas: {len(elements)}")
categories = []
for item in elements:
try:
category_name = item.query_selector("h6.card__title.heading").inner_text().strip()
except:
category_name = "Sin nombre"
try:
description = item.query_selector("div.card__description").inner_text().strip()
except:
description = "Sin descripción"
try:
link = item.query_selector("a").get_attribute("href")
if not link.startswith("http"):
link = urljoin(URL, link)
except:
link = "Sin enlace"
categories.append({
"nombre": category_name,
"descripcion": description,
"link": link
})
print(f"Fase de scraping completada. Obtenidas {len(categories)} categorías.")
return categories
Esta función automatiza el proceso de extracción, asegurando que se capturan todos los datos relevantes de la web.
Paso 3: Enriquecimiento de Descripciones con Azure AI Foundry
Una vez recopiladas las descripciones, se requiere enriquecerlas para ofrecer información más detallada y atractiva. Para ello, la función azure_foundry_enrich_batch se conecta a la API de Azure AI Foundry y envía un prompt específico que actúa como asistente turístico. El modelo responde con una versión mejorada de cada descripción.
def azure_foundry_enrich_batch(descriptions):
url = f"{AZURE_FOUNDRY_ENDPOINT}openai/deployments/{AZURE_FOUNDRY_DEPLOYMENT_NAME}/chat/completions?api-version=2024-10-21"
headers = {
"Content-Type": "application/json",
"api-key": AZURE_FOUNDRY_API_KEY
}
prompt_content = (
"Actúa como un asistente turístico especializado que enriquece descripciones de lugares en Tenerife. "
"A continuación tienes un array JSON con varias descripciones turísticas. "
"Devuélveme SOLO un array JSON, sin ningún formato markdown, sin explicaciones adicionales, "
"en el mismo orden y con la misma longitud, donde cada elemento sea "
"una versión más detallada y atractiva de la descripción original. "
f"Descripciones: {json.dumps(descriptions, ensure_ascii=False)}"
)
data = {
"messages": [
{"role": "system", "content": "Eres un asistente turístico especializado en Tenerife. Responde ÚNICAMENTE con JSON válido, sin markdown."},
{"role": "user", "content": prompt_content}
],
"max_tokens": 1000,
"temperature": 0.7
}
try:
response = requests.post(url, headers=headers, json=data, timeout=30)
if response.status_code == 200:
result = response.json()
content = result["choices"][0]["message"]["content"].strip()
json_pattern = r'\[.*\]'
json_match = re.search(json_pattern, content, re.DOTALL)
if json_match:
json_content = json_match.group()
enriched_descriptions = json.loads(json_content)
if isinstance(enriched_descriptions, list) and len(enriched_descriptions) == len(descriptions):
return enriched_descriptions
# Si no se encuentra el formato esperado, se realizan otros intentos de parseo
else:
error_msg = f"Error en la API: {response.status_code} - {response.text}"
print(error_msg)
return [error_msg for _ in descriptions]
except Exception as e:
error_msg = f"Excepción al llamar a la API: {e}"
print(error_msg)
return [error_msg for _ in descriptions]
Este paso transforma las descripciones básicas en versiones enriquecidas, haciendo el contenido más persuasivo y útil para futuros usuarios.
Paso 4: Vectorización de la Información mediante Embeddings
Para poder realizar búsquedas inteligentes y encontrar categorías similares, es fundamental transformar el texto en vectores numéricos. Usamos el modelo "text-embedding-3-small" de Azure OpenAI para generar estos embeddings, combinando el nombre y la descripción detallada de cada categoría.
def generate_embeddings(json_file_path):
print("Iniciando generación de embeddings...")
with open(json_file_path, 'r', encoding='utf-8') as f:
categories = json.load(f)
embedding_url = "https://<tu_endpoint_genérico>/openai/deployments/text-embedding-3-small-2/embeddings?api-version=2023-05-15"
headers = {
"Content-Type": "application/json",
"api-key": "<tu_api_key_genérica_para_embeddings>"
}
embeddings_results = []
total = len(categories)
for idx, category in enumerate(categories):
nombre = category.get('nombre', 'Sin nombre')
descripcion_detallada = category.get('descripcion_detallada', '')
texto = f"{nombre}. {descripcion_detallada}"
data = {
"input": texto,
"encoding_format": "float"
}
try:
response = requests.post(embedding_url, headers=headers, json=data, timeout=30)
if response.status_code == 200:
result = response.json()
embedding = result["data"][0]["embedding"]
embedding_result = {
"id": nombre,
"nombre": nombre,
"descripcion_detallada": descripcion_detallada,
"embedding": embedding
}
embeddings_results.append(embedding_result)
print(f"[{idx+1}/{total}] Embedding generado para: {nombre}")
else:
print(f"Error para '{nombre}': {response.status_code}")
except Exception as e:
print(f"Excepción para '{nombre}': {e}")
embeddings_file = "categorias_embeddings.json"
with open(embeddings_file, "w", encoding="utf-8") as f:
json.dump(embeddings_results, f, ensure_ascii=False, indent=4)
print(f"Embeddings guardados en '{embeddings_file}'")
return embeddings_results
La vectorización es la base para poder realizar comparaciones semánticas y ofrecer resultados de búsqueda relevantes.
Paso 5: Almacenamiento en Azure Blob y Table Storage
Una vez procesada la información, se almacena en dos orígenes de datos:
- Azure Blob Storage: Se sube el archivo JSON con las categorías y sus embeddings, lo que permite utilizarlo fácilmente como fuente de datos.
- Azure Table Storage: Los datos se guardan como entidades, permitiendo realizar consultas estructuradas y eliminar registros antiguos si es necesario.
Subida a Azure Blob Storage
def upload_to_blob_storage(file_path, container_name, blob_name):
try:
connect_str = os.getenv("AZURE_STORAGE_CONNECTION_STRING", "<tu_conexion_genérica>")
blob_service_client = BlobServiceClient.from_connection_string(connect_str)
try:
container_client = blob_service_client.get_container_client(container_name)
container_client.get_container_properties()
except Exception:
print(f"Creando contenedor '{container_name}'...")
blob_service_client.create_container(container_name)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=blob_name)
with open(file_path, "r", encoding="utf-8") as json_file:
json_content = json_file.read()
blob_client.upload_blob(json_content, overwrite=True, content_type="application/json")
print(f"Archivo '{file_path}' subido exitosamente a Blob Storage")
except Exception as e:
print(f"Error al subir el archivo: {e}")
Guardado en Azure Table Storage
def save_to_table_storage(json_file_path, table_name):
try:
connect_str = os.getenv("AZURE_STORAGE_CONNECTION_STRING", "<tu_conexion_genérica>")
table_service_client = TableServiceClient.from_connection_string(connect_str)
try:
table_client = table_service_client.get_table_client(table_name)
properties = table_client.get_table_properties()
print(f"Tabla '{table_name}' encontrada. Limpiando registros...")
for entity in table_client.list_entities():
table_client.delete_entity(partition_key=entity["PartitionKey"], row_key=entity["RowKey"])
except Exception as e:
print(f"Tabla no encontrada, creando nueva: {e}")
table_client = table_service_client.create_table(table_name)
with open(json_file_path, 'r', encoding='utf-8') as f:
categories = json.load(f)
import uuid
for category in categories:
unique_id = str(uuid.uuid4())
entity = {
"PartitionKey": "categories",
"RowKey": unique_id,
"id": unique_id,
"nombre": category.get('nombre', 'Sin nombre'),
"descripcion": category.get('descripcion', ''),
"link": category.get('link', ''),
"descripcion_detallada": category.get('descripcion_detallada', ''),
"contentVector": json.dumps(category.get('embedding', []))
}
table_client.create_entity(entity)
print("Datos guardados correctamente en Table Storage")
except Exception as e:
print(f"Error al guardar en Table Storage: {e}")
Conclusión y Próximos Pasos
En este primer artículo os muestro paso a paso cómo construir un agente inteligente que:
- Extrae información turística a través de webscraping.
- Enriquece las descripciones utilizando Azure AI Foundry.
- Vectoriza el contenido para futuras búsquedas inteligentes.
- Almacena los datos en Azure Blob y Table Storage, habilitando su uso en Azure AI Search.
El objetivo es transformar datos básicos en un conocimiento enriquecido y estructurado que, en una segunda parte, se integrará en Azure AI Search para ofrecer una experiencia de búsqueda personalizada y basada en inteligencia artificial. Este proceso no solo automatiza la recopilación y el enriquecimiento de la información, sino que también sienta las bases para soluciones en el ámbito turístico, facilitando la integración de múltiples servicios de Azure.
En el segundo artículo, profundizaremos en cómo configurar Azure AI Search y conectar estos datos con Copilot Studio para cerrar el circuito, permitiendo que los usuarios finales se beneficien de un sistema de búsqueda avanzado.
Espero que este tutorial os haya sido útil y que inspire nuevas ideas para aprovechar la potencia de Azure en la creación de soluciones. ¡Nos vemos en el próximo post!